Provider Names: O1 FTSO, Fly2Sonic, Flare Ocean, Civil FTSO, Anon2
Provider Delegation Addresses:
O1 FTSO: 0x229458a754cd1aeba8a0c87f59e22777d593b85a
Fly2Sonic: 0xe6caa2bca8b0e9004724e0600b38db52c17bcac30
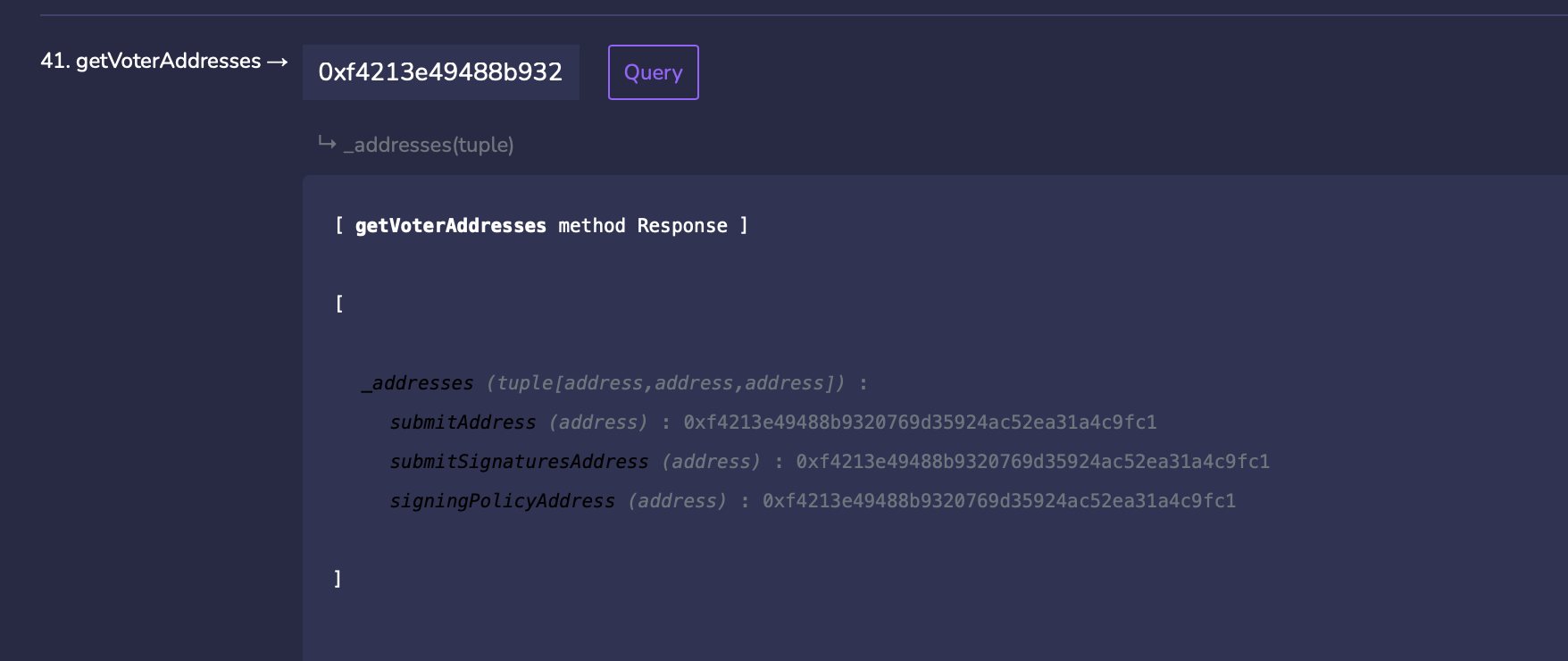
Flare Ocean: 0xf4213e49488b9320769d35924ac52ea31a4c9fc1
Civil FTSO: 0x733a73408d8e106b6ac999ccd9f3d308bcaeb7b5 (already voted on, awaiting Foundation decision)
Anon2: 0x814cd7d3cee516b8e0537085ecdeca7695d65c63 (already voted on, awaiting Foundation decision)
Network: Songbird
Overview: Common downtime among multiple (5) providers suggests they’re using the same infrastructure / data source / api.
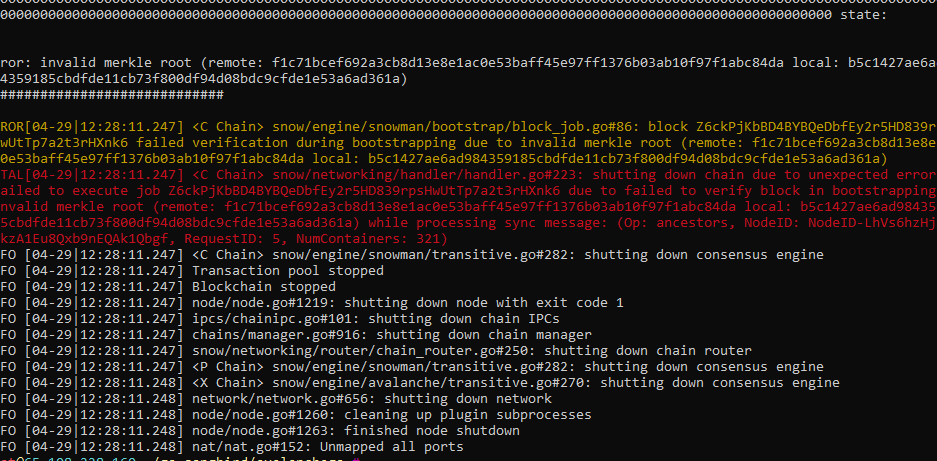
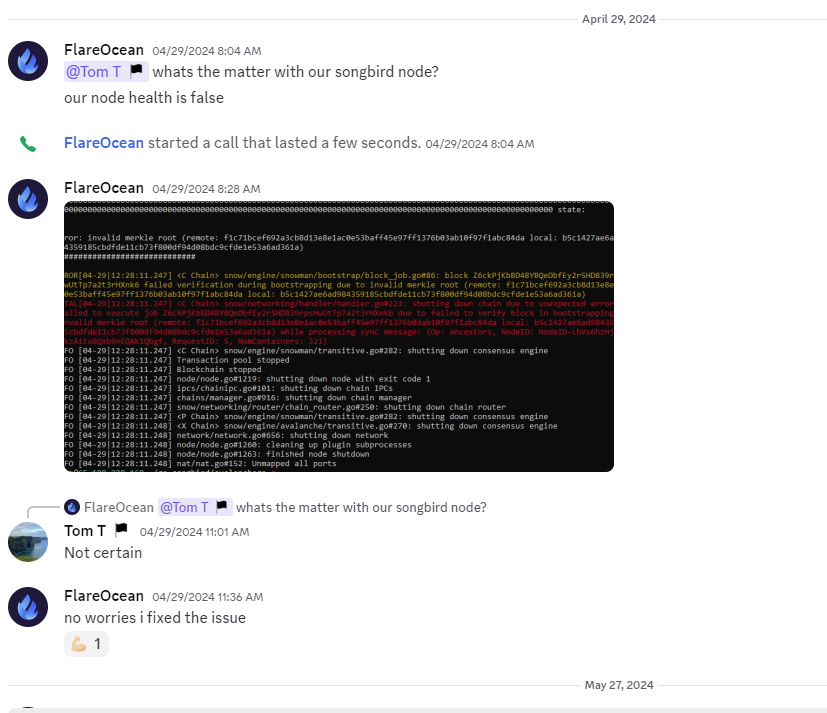
Evidence: Two pieces of evidence: the first shows downtime observed among the named providers, all starting within one epoch of each other and lasting many hours before returning independently. All 5 providers submit epoch 458607, 3 providers submit epoch 458608, all providers then experience downtime for ~5hrs before coming online independently over the subsequent 10hrs.
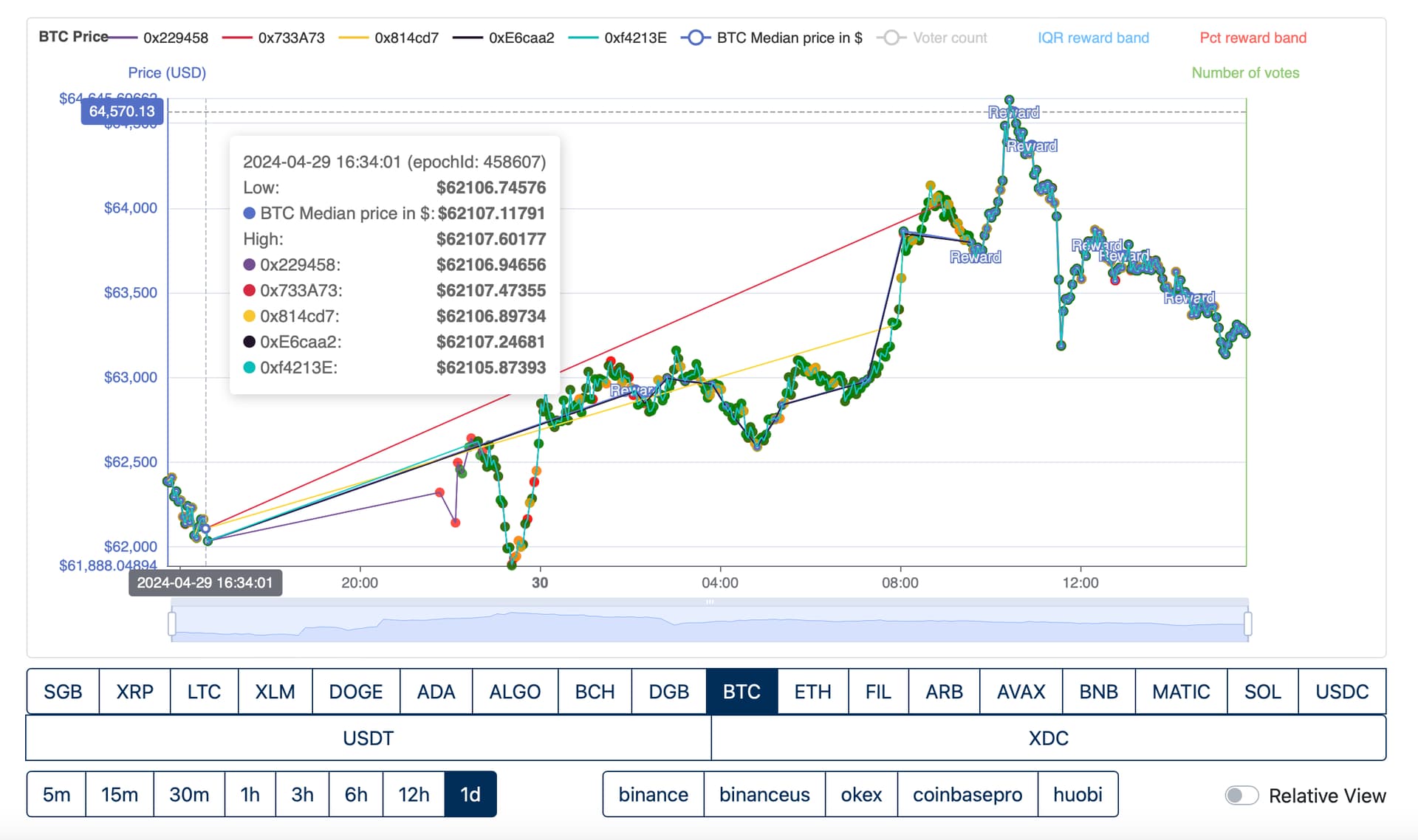
Downtime observed on all symbols, BTC in the above example and XRP in the below.
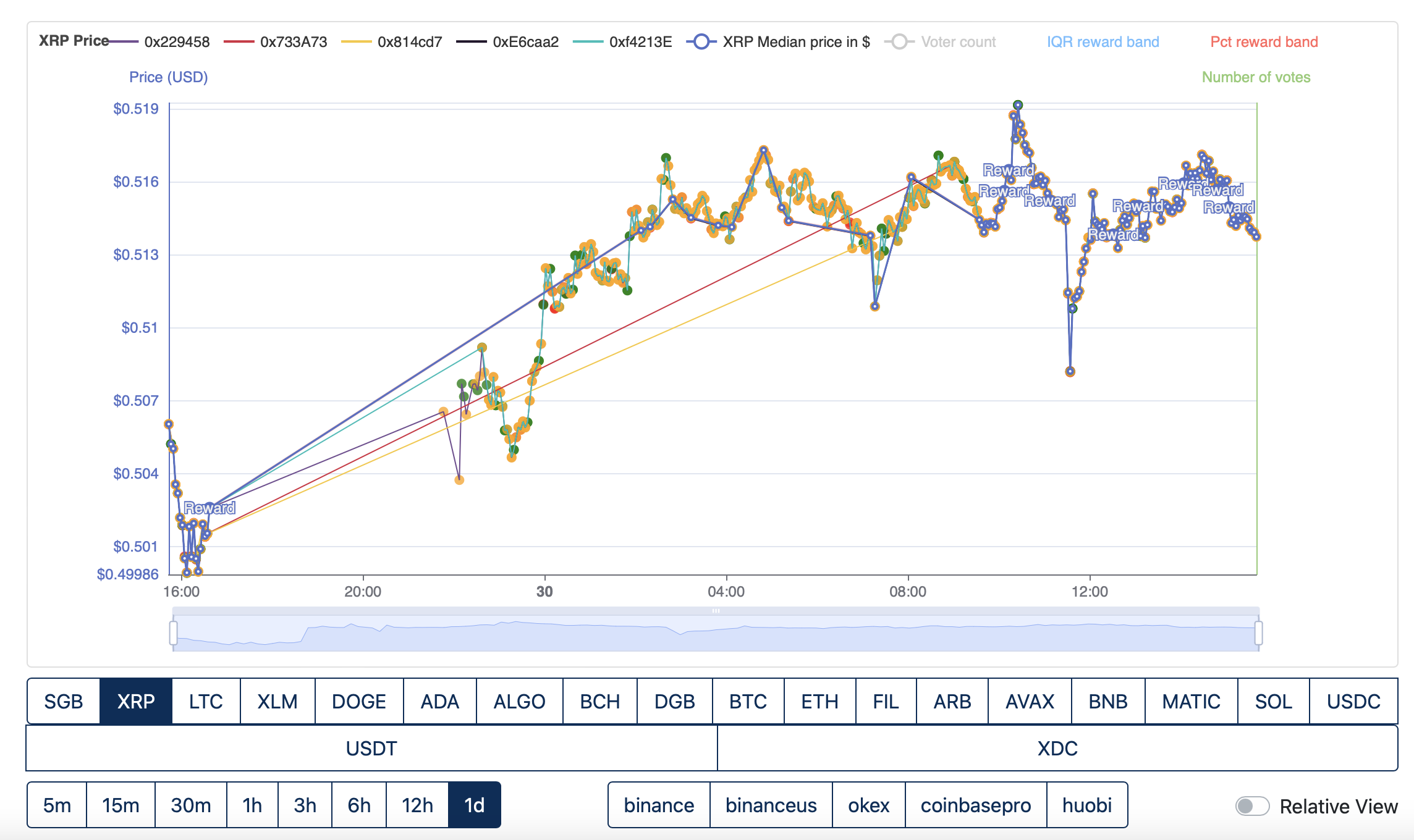
The second shows Fly2Sonic and O1 FTSO alternating their submissions over a period of approximately 10 hours, with neither submitting at the same time.
Both providers last submit together at epoch 357693.
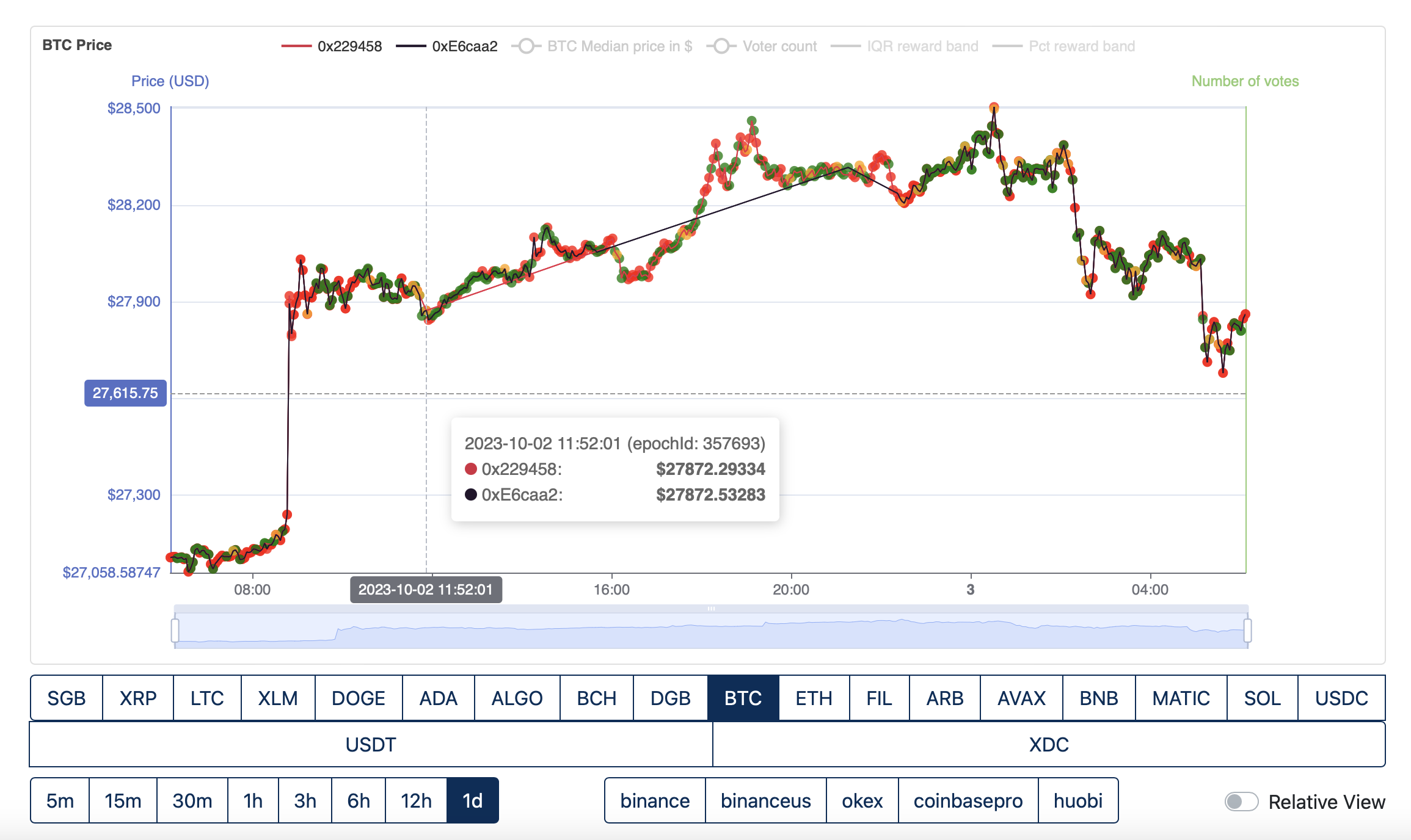
Fly2Sonic continues submitting until epoch 357770, O1 FTSO does not submit during this period.
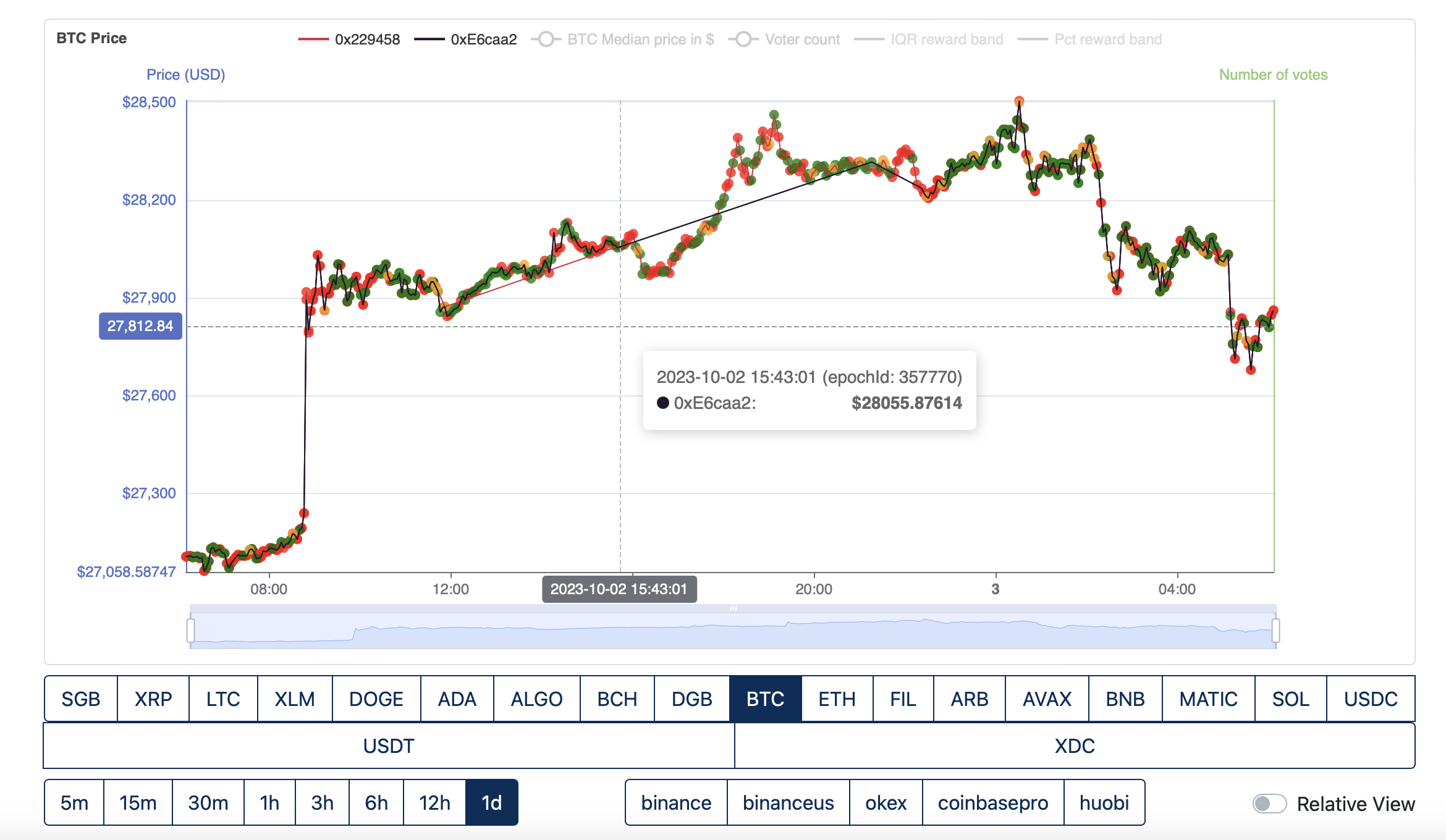
O1 FTSO then starts again at epoch 357771 and Fly2Sonic stops submitting.
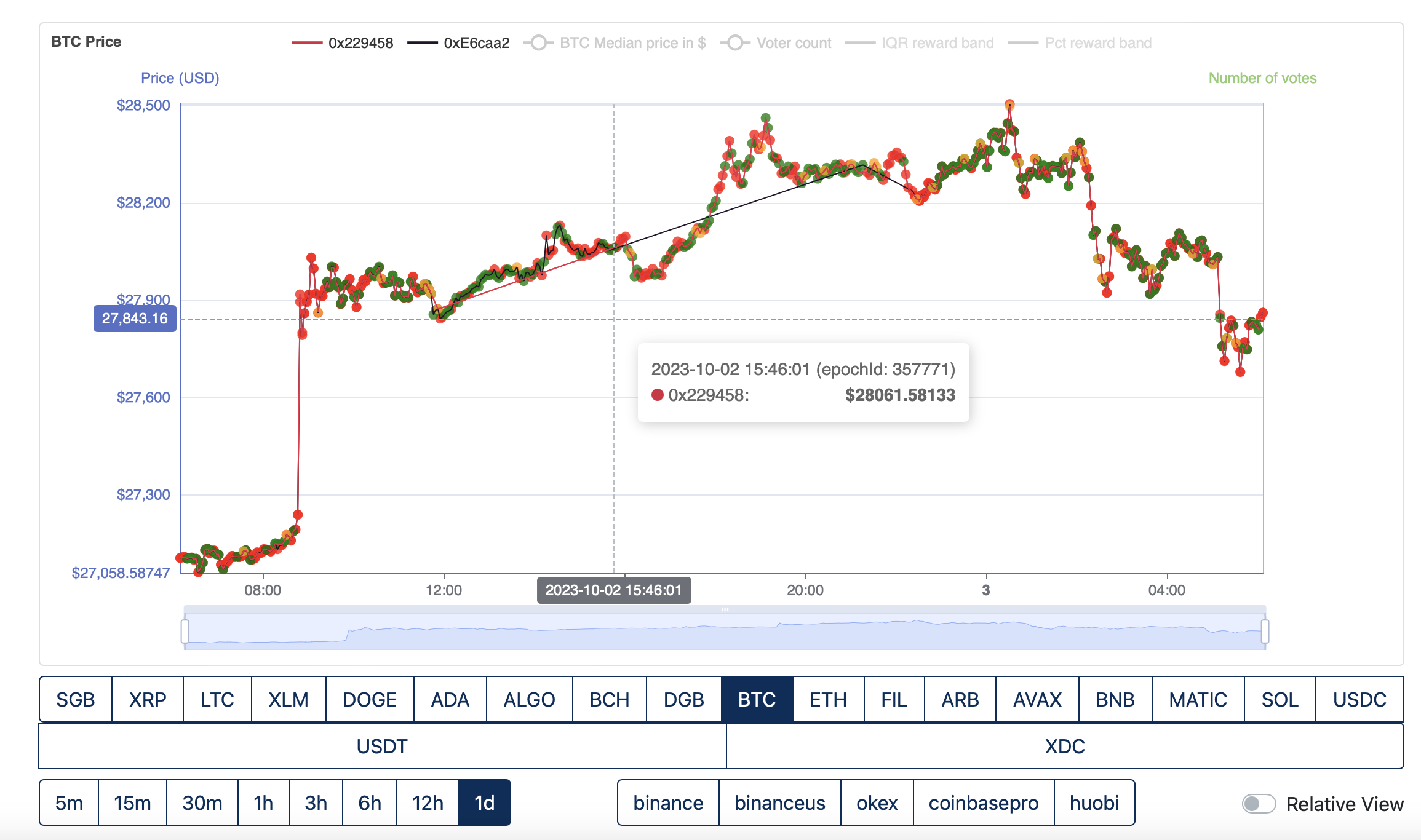
O1 FTSO continues to submit until 357879, neither provider submits epoch 357880.
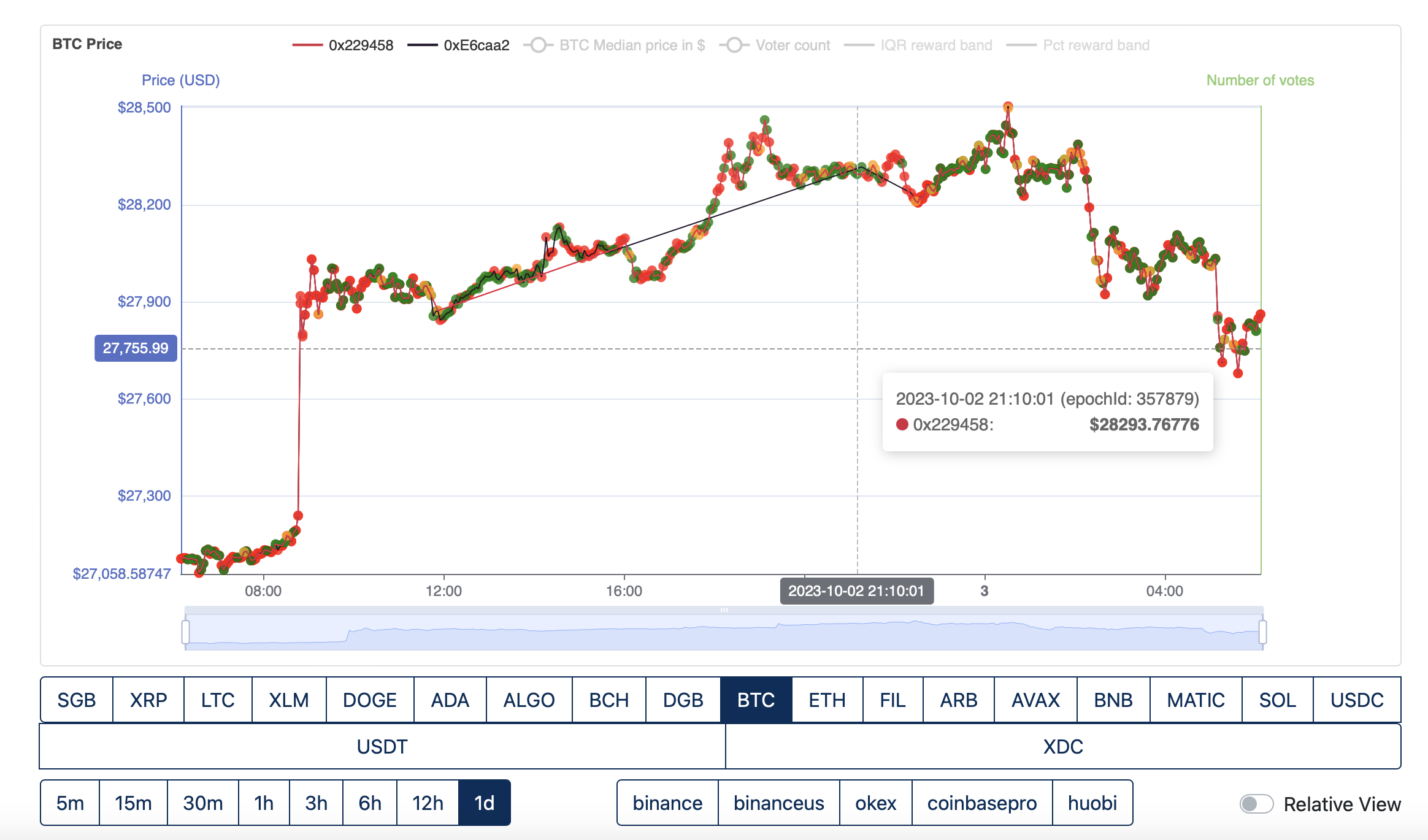
Fly2Sonic submit 357881, O1 FTSO do not. Neither submit 357882.
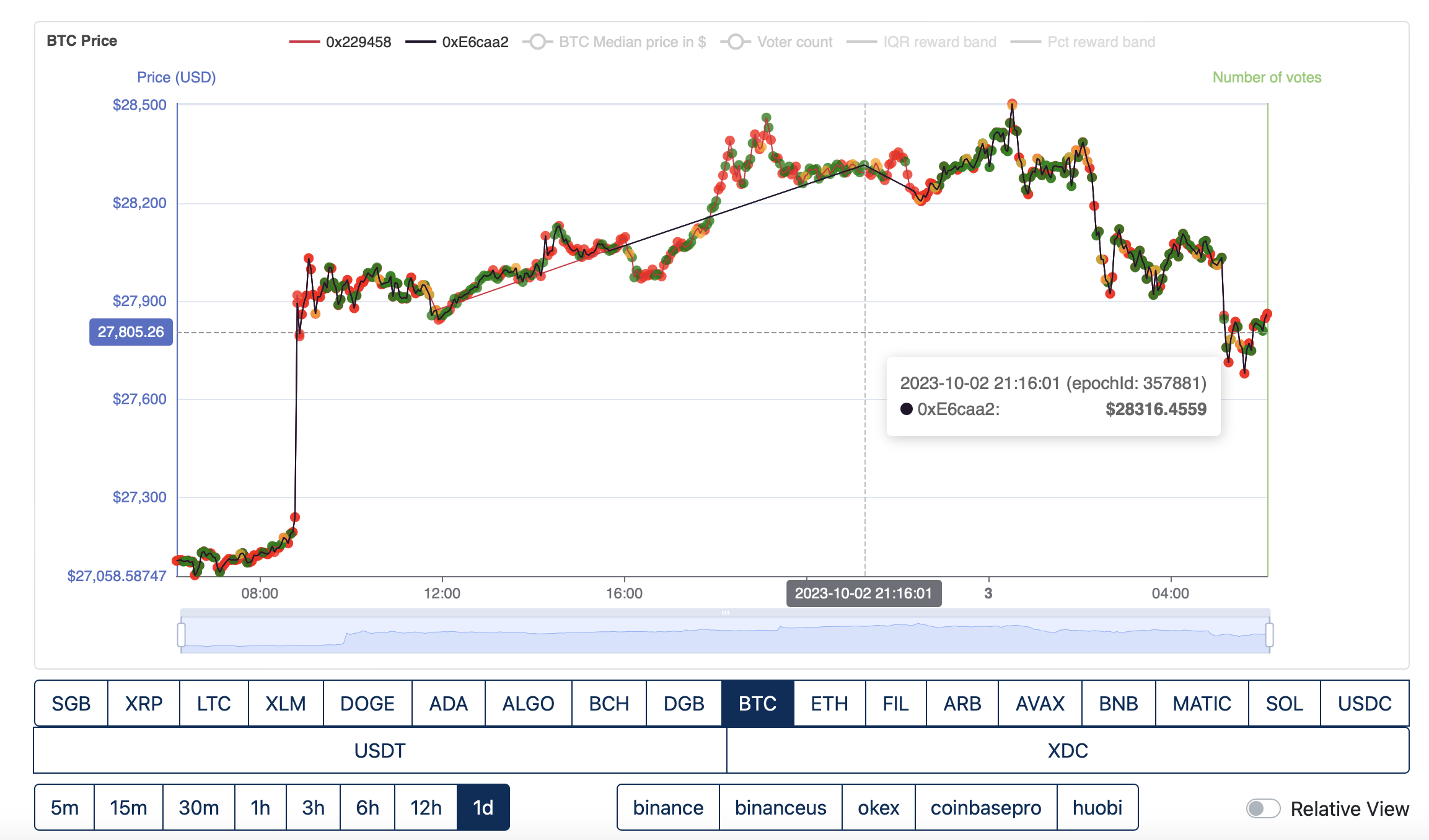
O1 FTSO submit from epoch 357883, Fly2Sonic do not.
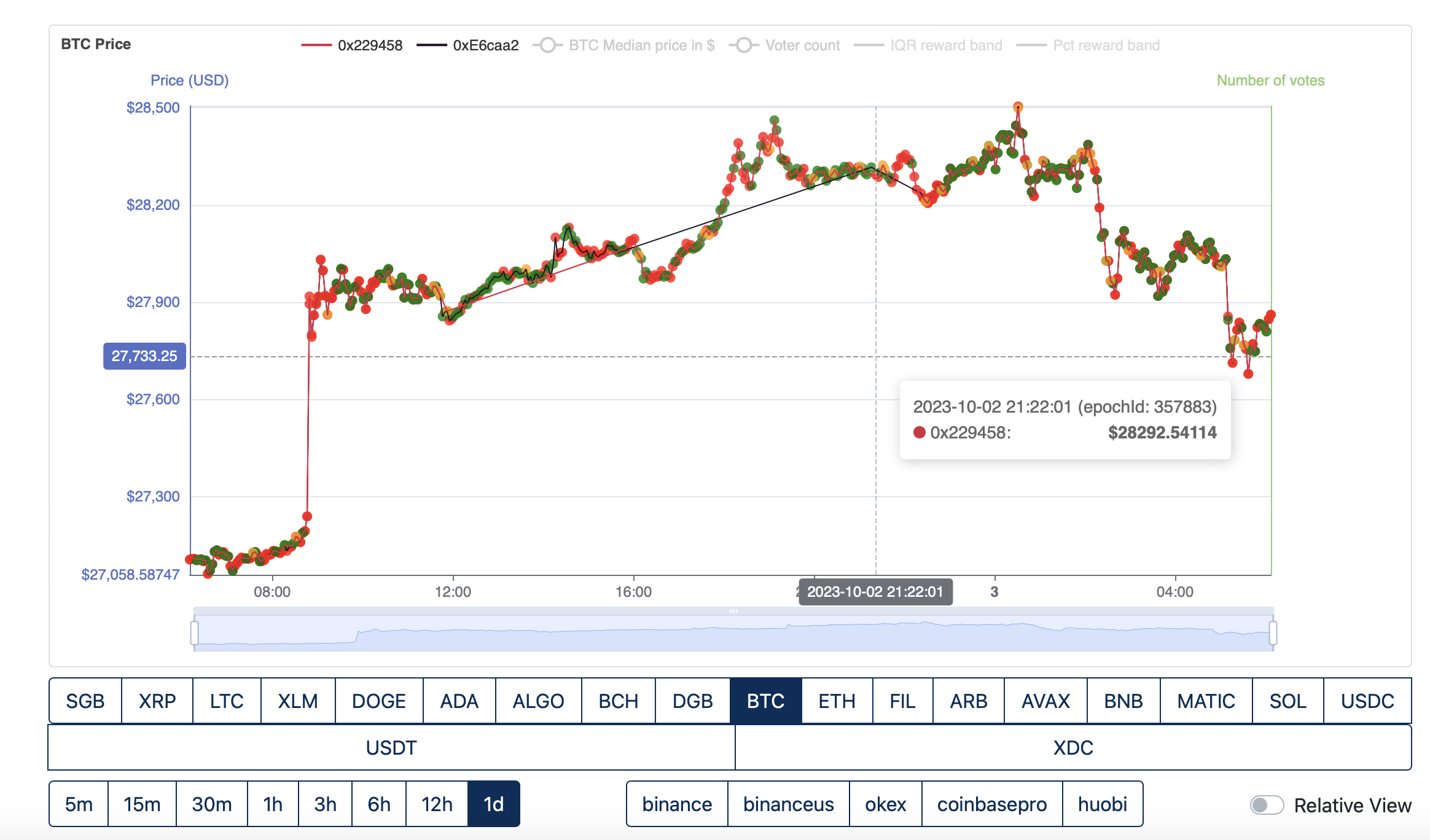
Both resume submitting from epoch 357908.
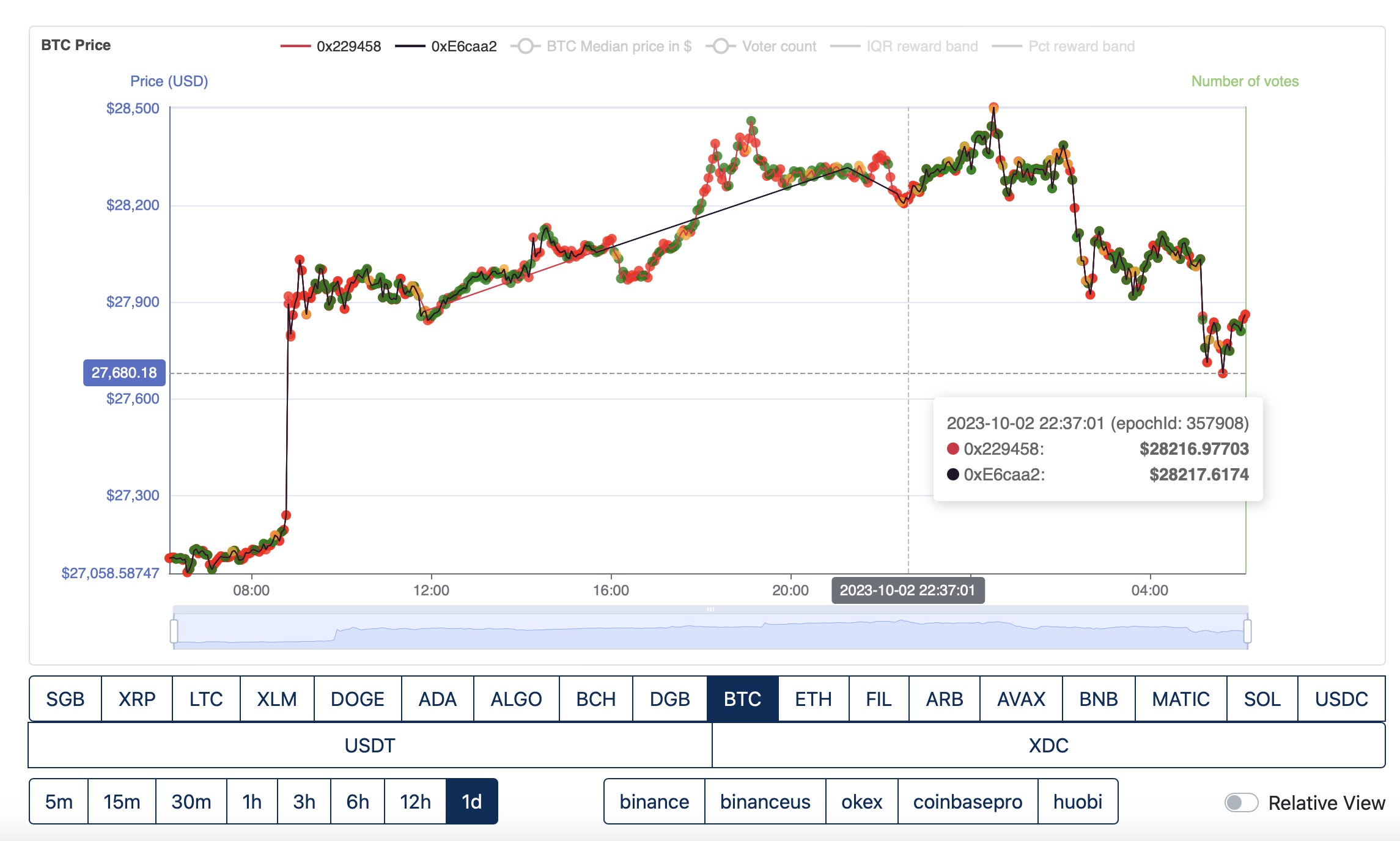
In both pieces of evidence the suggestion is these providers are sharing infrastructure, data feed or using the same pricing api.
1st Offence: Flare Ocean, Fly2Sonic.
Previously Chilled: O1 FTSO once. Civil FTSO and Anon2 chilled once with a ban decision pending.
Previous Chill Proposal Number: O1 FTSO (SMGP-14), Civil FTSO (SMGP-16, SMGP-24), Anon2 (SMGP-17, SMGP-25).
Timeframe for Open Discussion: 7 days
Request of Management Group Members: I respectively asks all MG members for input on the evidence provided in this proposal and to participate in subsequent on-chain voting following the discussion period. Depending on the feedback from the providers mentioned, proposals will be created for O1 FTSO, Fly2Sonic and Flare Ocean.
Request to the Flare Foundation: If voting meets quorum, I respectfully request that the Foundation action a two epoch chill of Fly2Sonic (0xe6caa2bca8b0e9004724e0600b38db52c17bcac30) on Songbird, Flare Ocean on both networks (0xf4213e49488b9320769d35924ac52ea31a4c9fc1 & 0x50bd2D0B457E27a481f97C4685d16EeB8B978155) and a permanent ban of O1 FTSO (0x229458a754cd1aeba8a0c87f59e22777d593b85a & 0xBE304C28F3a050486b9733AE56cB5541B16c007B) on both networks.
These actions should apply to both FTSO V1 and V2.
Both O1 FTSO and Flare Ocean have registered for V2, at this stage Fly2Sonic have not.
O1 FTSO
https://www.useyourspark.com/analytics/monitor
Flare Ocean